The Australian Faunal Directory (AFD) was an eye opener as it was the first serious use I'd made of CouchDB (now CouchBase). I'd played with replicating and forking data in 2010: Catalogue of Life and CouchDB, but the AFD project was bigger, and also inspired me to use web hooks to make the database editable. Suddenly this stuff started to look easy: no schema, simple web services, and tiny amounts of code.
The Australian Faunal Directory (AFD) was an eye opener as it was the first serious use I'd made of CouchDB (now CouchBase). I'd played with replicating and forking data in 2010: Catalogue of Life and CouchDB, but the AFD project was bigger, and also inspired me to use web hooks to make the database editable. Suddenly this stuff started to look easy: no schema, simple web services, and tiny amounts of code.ZooBank
So then my attention turned to ZooBank, which is "the official registry of Zoological Nomenclature, according to the International Commission on Zoological Nomenclature (ICZN)." ZooBank was proposed by Polaszek et al. (2005) in a short piece in Nature ("A universal register for animal names", doi:10.1038/437477a). By providing a registry of names for animals, ultimately it aims to help avoid embarrassing situations such as the example I recount in my paper on BioStor (doi:10.1186/1471-2105-12-187): a recent paper in Nature published the name Leviathan for an extinct sperm whale with a giant bite (doi:10.1038/nature09067), only for authors to have to publish an erratum with a new name (doi:10.1038/nature09381) when it was discovered that Leviathan had already been used for an extinct mammoth.
ZooBank is developed and run by Rich Pyle, and has some nice features, such as RDF export (via LSIDs), but like most taxonomic databases it doesn't link directly to the literature. Where are the DOIs? Where are links to BHL? Where is the ability to add these links? And why is it almost entirely about fish? (OK, I know the answer to that one).
CouchDB
But the thing which really got me thinking about using CouchDB to create a version of ZooBank was Rich Pyle's vision of having a distributed ZooBank, and his insistence on using ugly UUIDs in ZooBank identifiers (e.g., urn:lsid:zoobank.org:act:6BBEF50E-76B4-42EF-97B1-7029DBCD8257). As much as they are ugly, Rich has always argued that they make distributed systems easy because you don't need a centralised system to assign unique identifiers.
Anybody who has played with CouchDB will know that CouchDB uses UUIDs by default to create identifiers for database documents. It also excels at data synchronisation, and can run on platforms large and small (including mobile such as Android and iOS). This means a database could be updated on an iPhone or iPad without an Internet connection, then the data could be synchronised with other databases. Indeed, I developed this CouchDB clone of ZooBank on my MacBook, then pointed it at CouchDB running on my server and within minutes had an exact copy of the database running on the server. This ease of replication, together with the joy of schema-less design makes CouchDB seem an obvious fit to ZooBank.
Demo
You can see the ZooBank on CouchDB demo here. It's not a complete copy of ZooBank, but has most of it. I reuse the UUIDs issued by ZooBank, so that
http://zoobank.org:80/?uuid=6bbef50e-76b4-42ef-97b1-7029dbcd8257
becomes
http://iphylo.org/~rpage/zoobank/6bbef50e-76b4-42ef-97b1-7029dbcd8257
As usual it's all a bit crude, but has some nice features, such as links to BHL content with a built in article viewer I wrote for the AFD project:
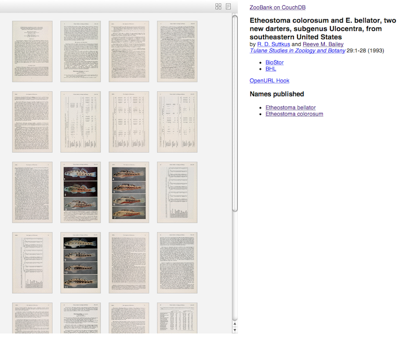 What's next?
What's next?At present only a fraction of the ZooBank references have external links, I hope to add more in the next few days, using both automatic scripts and the web hook interface. The search interface needs work, and being that ZooBank is about nomenclature and not taxonomy, it might be useful to add a classification (say from the Catalogue of Life) so that users can navigate around the names (and get a sense of how many are *cough* fish).
At present to display a reference I do one of four things:
- If reference is in BHL I use my article viewer
- If there is a freely available PDF online I display that using Google Docs PDF viewer
- If 1 and 2 don't apply, but there is a DOI then I resolve the DOI and display the result in an IFRAME (yuck)
- If none of 1-3 apply I display a blank rectangle
There are a couple ways we could improve this. The first is to enhance the display of BHL content by making use of the structure of the source DjVu files. Another is to make use of the XML now being made available by the journal Zookeys (see my blog post, and Pensoft's announcement that ZooKeys is now being archived by PubMed Central, complete with taxonomic markup). There are a lot of ZooKeys articles in ZooBank, so there's a lot of potential for embedding an article viewer that takes Zookeys XML and redisplays it with taxonomic names and references as clickable links that link to other ZooBank content. That way we approach the point where taxonomic literature becomes a first class citizen of a taxonomic database.